
기수 정렬 : 데이터가 모두 k 자릿수 이하의 자연수인 특수한 경우에 사용 가능
우선 가장 낮은 자릿수만 가지고 모든 수를 재배열(정렬)한다. 그런 다음 가장 낮은 자릿수는 잊어버리고 같은 방법으로 더 이상 자릿수가 남지 않을 때까지 계속한다.

시간 복잡도 : O(N)
계수 정렬 : 데이터의 크기 범위가 제한되어 정수 형태로 표현할 수 있을 때 사용 가능
⚠️ 계수정렬은 직접 데이터의 값을 비교한 뒤에 위치를 변경하며 정렬하는 방식 (비교 기반의 정렬 알고리즘)이 아니다.
1) 가장 큰 데이터 + 1 크기의 모든 원소가 담길 수 있는 하나의 리스트를 생성
2) 처음에는 리스트의 모든 데이터가 0이 되도록 초기화한다.
3) 그 다음 데이터를 하나씩 확인하며 데이터의 값과 동일한 인덱스의 데이터를 1씩 증가
4) 입력 배열의 각 원소에 대해 count 리스트에 어느 인덱스에 들어가야하는지 조회
( 참고 애니메이션 : https://www.cs.miami.edu/home/burt/learning/Csc517.091/workbook/countingsort.html )

package sorting;
public class sorting04 {
public static final int MAX_VALUE = 9;
public static void main(String[] args) {
int[] arr = {7, 5, 9, 0, 3, 1, 6, 2, 9, 1, 4, 8, 0, 5, 2};
int[] cnt = new int[MAX_VALUE + 1];
for (int i = 0; i < arr.length; i++) {
cnt[arr[i]] += 1; // 각 데이터에 해당하는 인덱스의 값 증가
}
for (int i = 0; i <= MAX_VALUE; i++) {
for (int j = 0; j < cnt[i]; j++) {
System.out.print(i + " ");
}
}
}
}시간 복잡도 : O(N+K)
데이터의 개수 : N, 데이터 중 최대값의 크기 : K
리스트의 각 인덱스에 해당하는 값들을 확인할 때 데이터 중 최댓값의 크기만큼 반복을 수행해야 함
따라서 데이터의 범위만 한정되어 있다면 효과적으로 사용할 수 있으며 항상 빠르게 동작한다.
현존하는 정렬 알고리즘 중에서 기수 정렬과 더불어 가장 빠름
공간 복잡도
계수 정렬은 때에 따라서 심각한 비효율성을 초래함. (ex. 데이터 수는 적으나 최소 최대값의 차이가 클 때)
동일한 값을 가지는 데이터가 여러 개 등장할 떄 적합 (ex. 100점 맞은 학생이 여러 명인 성적 정렬)
반면에 앞서 설명한 퀵 정렬은 일반적인 경우에서 평균적으로 빠르게 동작하기 때문에 데이터의 특성을 파악하기 어렵다면 퀵 정렬을 이용하는 것이 유리함
즉, 계수 정렬은
1. 데이터의 크기가 한정되어 있고
2. 데이터의 크기가 많이 중복되어 있을 때 유리
정렬 라이브러리
package sorting;
public class sorting04 {
public static final int MAX_VALUE = 9;
public static void main(String[] args) {
int[] arr = {7, 5, 9, 0, 3, 1, 6, 2, 9, 1, 4, 8, 0, 5, 2};
int[] cnt = new int[MAX_VALUE + 1];
for (int i = 0; i < arr.length; i++) {
cnt[arr[i]] += 1; // 각 데이터에 해당하는 인덱스의 값 증가
}
for (int i = 0; i <= MAX_VALUE; i++) {
for (int j = 0; j < cnt[i]; j++) {
System.out.print(i + " ");
}
}
}
}정렬 라이브러리는 항상 최악의 경우에도 O(NlogN)을 보장한다.
사실 우리가 직접 퀵 정렬을 구현할 때보다 더욱더 효과적임
(문제에서 별도의 요구가 없이 단순 정렬해야하는 경우 > 기본 정렬 라이브러리 사용
데이터의 범위가 한정되어 있으며 더 빠르게 동작해야 할 때 > 계수 정렬)
📚 실전문제 ) 위에서 아래로
수열을 내림차순으로 정렬하는 프로그램을 만드시오

package sorting;
import java.util.*;
public class sorting06 {
public static void main(String[] args){
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
Integer[] arr = new Integer[n];
for (int i = 0; i < n; i++) {
arr[i] = sc.nextInt();
}
Arrays.sort(arr, Collections.reverseOrder());
for(int i = 0; i < n; i++) {
System.out.print(arr[i] + " ");
}
}
}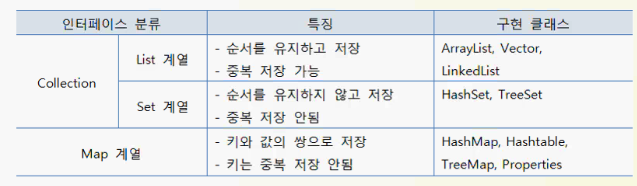
컬렉션이란? 자바에서 자료구조를 표현하는 인터페이스
Collection의 자료형에는 기본 타입은 올 수 없다.
자바의 자료형은 크게 기본 타입(primitive type)과 참조 타입(reference type)으로 나누어진다.
-기본 타입 : char, int, float, double, boolean 등
- 참조 타입 : String, Integer, Boolean, List 등 클래스 및 인터페이스
일반적으로 코딩 테스트에서 정렬 알고리즘이 사용되는 경우
1. 정렬 라이브러리로 풀 수 있는 문제 : 단순히 정렬 기법을 알고 있는지 물어보는 문제
2. 정렬 알고리즘의 원리에 대해서 물어보는 문제 : 선택/삽입/퀵 정렬 등의 원리를 알아야함
3. 더 빠른 정렬이 필요한 문제 : 퀵 정렬 기반의 정렬 기법으로는 풀 수 없으며 계수 정렬 등의 다른 정렬 알고리즘을 이용하거나 문제에서 기존에 알려진 알고리즘의 구조적인 개선을 거쳐야 풀 수 있다.
'알고리즘' 카테고리의 다른 글
| [알고리즘] 해시맵(HashMap) (0) | 2023.02.07 |
|---|---|
| [알고리즘] Scanner VS BufferedReader (0) | 2022.11.28 |
| 우선순위 큐(Prioriy Queue) (0) | 2022.11.17 |